
BASICS of RENDERING ~ What’s Right for You?

CUDA vs OpenGL
What is CUDA?

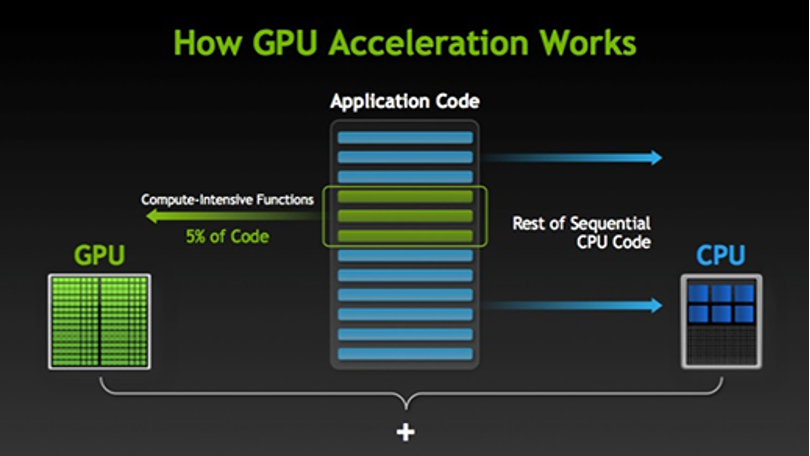
CUDA was created by graphics card (GPU) manufacturer, Nvidia. In simple terms, CUDA allows programs to use the brains of the GPU as a sub-CPU. Your CPU passes certain tasks off to the CUDA enabled card. The GPU specializes in quickly calculating effects like lighting, movement and interaction. GPUs are specifically designed to process information as fast as possible, even sending it through multiple lanes at once– as if you had four checkout lanes at the supermarket for one shopping cart. The results are then passed back to the CPU, which has moved on to bigger and better things.
Since CUDA’s primary functionality lies in calculation, data generation and image manipulation, effects processing, rendering and export times can be greatly reduced, especially when up or down-scaling. Image analysis can also be improved, as well as simulations like fluid dynamics and predictive processes like weather patterns. CUDA is also great at light sources and ray-tracing. All of this means functions similar to rendering effects, video encoding, conversions and more… will process much faster.
CUDA technology is proprietary to Nvidia so you’ll need a GPU manufactured by them to take advantage of it. If you have for example an iMac Pro, CUDA is currently not an option since Apple workstations only come with AMD GPUs. This may change at some point down the road. There are third party options but Apple only uses AMD in their packages. You’ll also find that fewer programs support CUDA than its alternative counterpart, OpenCL.
What’s OpenCL?
OpenCL (Open Computer Language) is a relatively new technology and can be considered an alternative to CUDA. It is an “open”, royalty-free standard for cross-platform, parallel programming of diverse processors found in personal computers, servers, mobile devices and embedded platforms. This means that anyone can use it in hardware or software without paying a licensing fee for the use of the technology. Whereas CUDA uses the GPU as a co-processor, OpenCL will pass off the information entirely, using the GPU more as a separate general-purpose peer processor. It’s a minor philosophical distinction, but there’s a quantifiable difference. For the programmer, it’s a little bit harder to code. As a user, you are not tied to any one vendor, and support is so widespread that most programs don’t even mention its adoption.
As we have already stated, the main difference between CUDA and OpenCL is that CUDA is a proprietary  framework created by Nvidia and OpenCL is open source. Each of these approaches has its own pros and cons.
framework created by Nvidia and OpenCL is open source. Each of these approaches has its own pros and cons.
The general consensus is that if your application of choice supports both CUDA and OpenCL, go with CUDA as it will yield better performance results. The main reason for this is that Nvidia provides top quality support to software application developers who choose to use CUDA acceleration, therefore the integration is always fantastic. For example, if we look at the Adobe CC, which supports both CUDA and OpenCL, CUDA accelerates more features and provides better acceleration to the features that both frameworks are able to power. If we look at Premiere Pro CS6, without CUDA only software-based playback is available. For further reading, in a forum thread on Creative Cow, an Adobe employee stated that in most cases CUDA would out-perform OpenCL.
Obviously, because CUDA is a proprietary framework it requires Nvidia’s support and time to integrate it into applications, this means that the functionality is always good. However, CUDA is not as easy for applications to adopt as OpenCL. Regardless, CUDA is still supported by a wide variety of applications and the list continues to grow.
As an easy rule of thumb… if your app supports CUDA, grab an Nvidia card, even if it also supports OpenCL.
Since we’ve recommended that if your software supports both OpenCL and CUDA, go for CUDA, what if OpenCL is your only choice? Simply put, go for it. For example, Final Cut Pro X only supports OpenCL, and we usually recommend that our users put AMD OpenCL cards into their systems if they use the popular video editing app. On a whole OpenCL integration generally isn’t as tight as CUDA but OpenCL will still produce significant performance boosts when used and is far better than not using GPGPU at all.
If your software application(s) split their support between CUDA and OpenCL, we recommend using a recent Nvidia card. With an Nvidia setup, you will get the most out of your CUDA enabled apps while still having good OpenCL capability in non-CUDA apps.
Right now CUDA and OpenCL are the leading GPGPU frameworks. CUDA is a closed Nvidia framework, it’s not supported in as many applications as OpenCL (though still supported widely), but where it is integrated top quality Nvidia support ensures unparalleled performance. OpenCL is open-source and is supported in more applications than CUDA. However, support is often lack-luster and it does not currently provide the same performance boosts as CUDA.
CPU vs GPU
- GPUs have more core processors than CPU but each processor in the GPU runs relatively slower than the CPU processor.
- CPU is preferred when one requires a high degree of precision and an output devoid of ‘noise’.
- CPU cores are faster than GPU only on a per core basis. CPU cannot handle multiple data streams but can perform more advanced operations on a single stream. Heavy complex processing in a single stream is not appropriate for GPU render.
- Lower hardware costs. One workstation can theoretically replace up-to 20 CPU machines put together.
- Increasing the size of CPU render farms do not substantially reduce render times relative to investment. GPU render yields faster processing for a relatively low investment.
Workstations & Systems Overview
Many of the most popular CG software applications have advanced multi-feature toolsets. They all perform modeling and animation tasks better when run on workstations that offer high CPU core speeds with core count not an important factor. Rendering, however, generally benefits from workstations that have a high core count where core speed is not an important factor. Historically speaking, higher CPU core count generally meant slower clock speeds.
To address these issues, Intel introduced “Turbo Boost” technology on many of their processors. “Turbo ![]() Boost” automatically adjusts core clock speed based on the number of cores active at any given time. For example, when only a few cores are working during modeling or animation, the core runs at higher speeds. When rendering, all cores are active and run at a lower clock speed. Creative Computing Solutions incorporates AMD & Intel “Turbo Boost” technology into many of its computer workstation.
Boost” automatically adjusts core clock speed based on the number of cores active at any given time. For example, when only a few cores are working during modeling or animation, the core runs at higher speeds. When rendering, all cores are active and run at a lower clock speed. Creative Computing Solutions incorporates AMD & Intel “Turbo Boost” technology into many of its computer workstation.
Clock speed, multi-core, hyper-threading, dual processor systems – there is a lot to consider! We’re going to break these subjects down in a way that everyone can understand. Hopefully, this will help you decide which processor is right for your system.
CPU Clock Speed
Many people consider the CPU as the brains of a computer system. However, it is more accurate to describe it not as the brains but as the brawn. If computing is a car then the CPU is the engine. The higher the clock speed, the faster the car (system) will go. Clock speed is measured in GHz (gigahertz) – a higher number means a faster clock speed.
To run your applications, the CPU must continually complete calculations, if you have a higher clock speed, you can compute these calculations quicker and applications will run faster and smoother.
Multiple Cores & Multiple Processors
Up until the early 2000’s virtually all processors on the market were single core. Clock speed ruled the roost and the fastest processor was always the best choice. Today processors have multiple cores and systems are built with multiple processors each with multiple cores. Multi-core processors became popular as it became increasingly difficult to increase clock speed on single core processors. Rather than working tirelessly for an extra 0.1GHz of clock speed, manufacturers instead added more identical processing units to single processors.
A core is a single processing unit. Multi-core processors have multiple processing units. So a dual-core 3.0GHz processor has two (2x) processing units each with a clock speed of 3.0GHz. A six-core 3.0GHz  processor has six (6x) processing units each with a clock speed of 3.0GHz. Does this mean your programs will run six times faster than with a single core 3.0GHz processor? Well, not exactly… if your application supports multicore and multithreaded processing and rendering then yes. Some applications still only utilize a single core because of the method required to render out the project.
processor has six (6x) processing units each with a clock speed of 3.0GHz. Does this mean your programs will run six times faster than with a single core 3.0GHz processor? Well, not exactly… if your application supports multicore and multithreaded processing and rendering then yes. Some applications still only utilize a single core because of the method required to render out the project.
Multi-Threading & Hyper-Threading
We’ve discussed multi-cores and multi-processors and how they may help applications run faster. This is where multi-threading and hyper-threading come into play. Multi-threading is the ability of a single core in a multi-core processor to provide multiple threads concurrently. When applications are written with multi-threading in mind, they can benefit from multiple cores and see significant performance increases over non-multi threaded processors.
*CCS offers a number of solutions that are optimized for CPU, CPU/GPU & GPU Render Applications. For detailed information CLICK HERE.
*For more information about AMD & Intel CPU Performance and to Review In-House CPU Render Benchmarks Test Results, CLICK HERE.